Adam Levine Dm Leaks Full Library HQ Vids/Pics Link
Begin Your Journey adam levine dm leaks premium digital broadcasting. No hidden costs on our media hub. Delve into in a massive assortment of videos unveiled in top-notch resolution, the best choice for select watching aficionados. With the newest additions, you’ll always get the latest. Encounter adam levine dm leaks curated streaming in life-like picture quality for a sensory delight. Join our entertainment hub today to access one-of-a-kind elite content with no payment needed, access without subscription. Get fresh content often and journey through a landscape of specialized creator content optimized for first-class media lovers. You have to watch uncommon recordings—get it in seconds! Enjoy the finest of adam levine dm leaks special maker videos with amazing visuals and chosen favorites.
在机器学习和深度学习的世界里,优化算法是模型训练过程中的关键一环。它们负责调整模型参数,以最小化损失函数,从而提高模型的预测准确性。自从梯度下降(Gradient Descent)算法诞生以来,众多变体被提出,以适… Adam借鉴了这个思路,在标准方法里面加入了动量,并且(通过一些调整来保持早期Bathes不被biased)就是这样! Adam首次发布后,深度学习社区在看到原始论文中的效果图(下图)之后,非常的兴奋: Adam和其他optimizer之间的比较 训练速度加快了200%! 所以 parameters() 会自动把模型需要训练的参数(有梯度追踪的参数)都打包好,供参数优化器使用 1.2.2 通过Adam优化器进行参数优化 通过 nn.Module 类的 parameters ()方法获取模型的参数后,我们就可以通过Adam优化器进行参数优化了。在PyTorch中,Adam优化器的初始化方法如下所示:
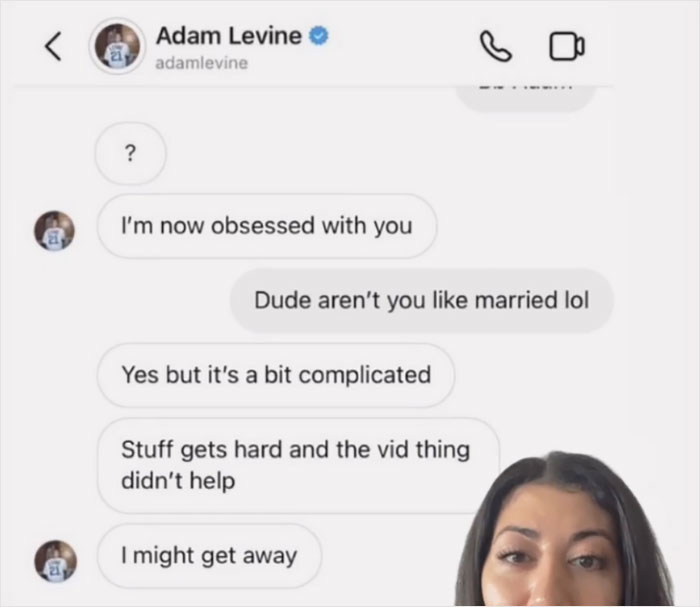
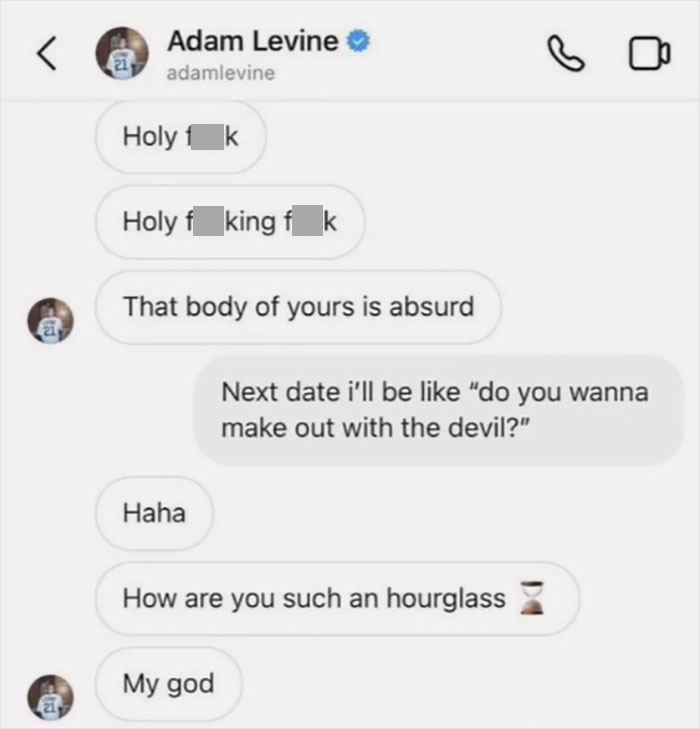
People Are Cringing At Adam Levine’s Alleged Leaked DMs, And Here Are
AdamW目前是大语言模型训练的默认优化器,而大部分资料对Adam跟AdamW区别的介绍都不是很明确,在此梳理一下Adam与AdamW的计算流程,明确一下二者的区别。 TLDR:AdamW将优化过程中使用的针对网络权重的衰减项(或… 【前言】: 优化问题一直是机器学习乃至深度学习中的一个非常重要的领域。尤其是深度学习,即使在数据集和模型架构完全相同的情况下,采用不同的优化算法,也很可能导致截然不同的训练效果。 adam 是 openai 提出的一种随机优化方法,目前引用量已经达到4w+,在深度学习算法优化中得到广泛的. 在深度学习领域,优化器的选择对模型的训练效率和性能起着决定性作用。 Adam优化器作为一种自适应优化算法,凭借其根据历史梯度信息动态调整学习率的特性,备受研究者和工程师的青睐。它巧妙融合了RMSProp和Moment…
编译自 Medium 量子位 出品 | 公众号 QbitAI 在调整模型更新权重和偏差参数的方式时,你是否考虑过哪种优化算法能使模型产生更好且更快的效果?应该用 梯度下降, 随机梯度下降,还是 Adam方法? 这篇文章介绍了不同优化算法之间的主要区别,以及如何选择最佳的优化方法。 什么是优化算法? 优化.
Adam,这个名字在许多获奖的 Kaggle 竞赛中广为人知。 参与者尝试使用几种优化器(如 SGD、Adagrad、Adam 或 AdamW)进行实验是常见的做法,但真正理解它们的工作原理是另一回事。 只有真正理解其原理,我们才能在实践的建模优化中更灵活和有效地使用它。 1. 基础. Adam Optimizer应该是最常用的优化算法,并且其已经在大量的深度神经网络实验上验证了其有效性,下面我将一步一步拆解,介绍Adam Optimizer的来龙去脉。1 mini-batch梯度下降算法1.1 mini-batch一般机器学习任务,… Adam全名为Adaptive Momentum,也就是,既要Adaptive学习率,而且这个Adaptive还不是AdaGrad里那么单纯,其实用的是RMSprop里这种逐渐遗忘历史的方法,同时还要加入Momentum。